DeepSeek开源第四弹炸场!梁文锋带队“手撕”AI训练瓶颈!
DeepSeek开源第四弹炸场!梁文锋带队“手撕”AI训练瓶颈!
一场技术革命,正在重塑AI江湖的生存法则,英伟达股价都跟着抖三抖!

DeepSeek与英伟达
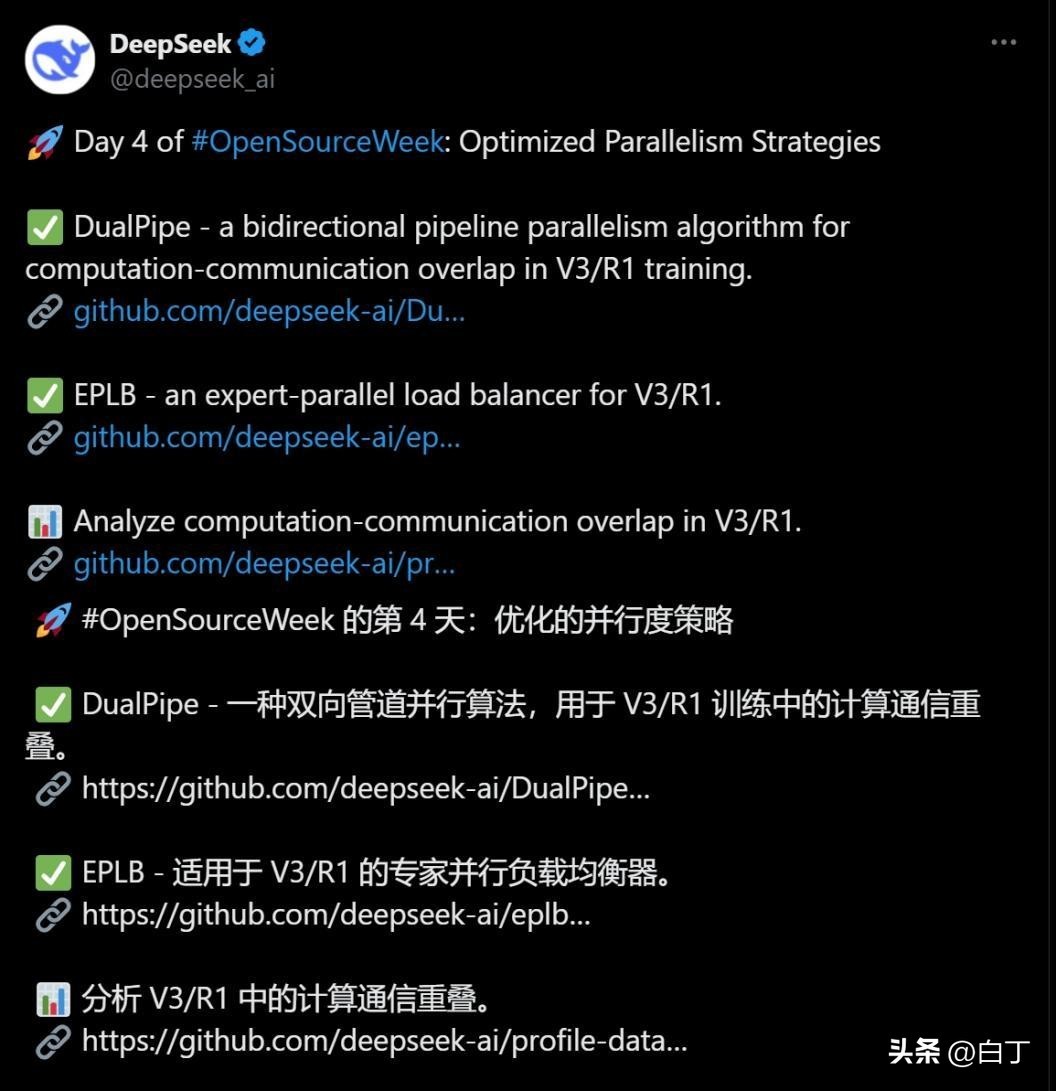
2025年2月27日,AI圈迎来开年“最硬核”事件:DeepSeek开源周第四弹横空出世,三项堪称“训练加速神器”的技术组合拳,直接把大模型研发成本拉低40%,连英伟达股价都应声跌了10%。更绝的是,创始人梁文锋亲自下场写代码,网友直呼:“这波操作,给AI训练装上了涡轮增压!”
第四弹
一、技术亮剑:三个“核弹”如何改写训练规则?
1. DualPipe:高铁+得来速,训练速度飙到2.7倍
想象一下,传统AI训练像早高峰的单行道,前向计算和反向传播必须排队等“放行”;而DualPipe就像双向高铁,数据在计算和通信阶段“边走边吃早餐”,直接砍掉30%的空闲时间。更绝的是,它还借鉴了麦当劳得来速的设计——数据到站即处理,无需等待!

高铁速度
效果有多猛?
DeepSeek-V3的预训练成本仅557.6万美元,比同类模型节省40%。有开发者实测:用上DualPipe后,密集模型训练时间从135小时缩至50小时,直接飙到2.7倍速。
2. EPLB:AI界的“春运指挥中心”,资源利用率飙升20%
在MoE模型中,专家负载不均是个“老大难”。EPLB就像春节抢票系统,动态调整专家分配,把“80%任务挤在20个专家”的惨状,优化成50个专家均衡上阵。

指挥
实操案例:
处理100个专家任务时,传统方法有80%负载集中在20个专家,而EPLB能将其分散到50个专家,GPU利用率提升20%。难怪网友调侃:“这简直是给GPU装上了智能减肥药!”
3. Profile-Data:性能分析“照妖镜”,让优化有据可依

照妖镜
DeepSeek直接甩出训练和推理框架的“体检报告”,用可视化数据展示通信-计算重叠策略的底层细节。开发者只需打开Chrome浏览器,就能像看体检报告一样,快速定位性能瓶颈。
二、行业地震:中小团队要“弯道超车”,英伟达急得直跺脚?

弯道超车
1. 开源“核弹”让巨头颤抖
DeepSeek这次开源的,可不是“边角料”:DualPipe、EPLB直接优化了GPU利用率,相当于公开了“如何用1块钱掰出10块钱效果”的秘籍。有从业者直言:“闭源公司再不跟进,客户就要被抢光了!”更狠的是,DeepSeek还宣布夜间API价格打5折,进一步挤压竞争对手的利润空间。
2. 英伟达股价三连跌,算力焦虑浮出水面

英伟达
消息一出,英伟达股价3天跌去10%。市场恐慌的逻辑很直白:如果AI训练能更高效地利用现有显卡,那未来还有多少人会买更贵的H100/H200?毕竟,DeepSeek-V3仅用278.8万H800 GPU小时就完成了训练,成本仅为行业均值的1/3。
三、未来战局:R2模型成关键变量,中国团队正在改写规则
1. R2模型或成“AI分水岭”

R2模型有望4月
DeepSeek内部消息称,原计划5月发布的R2模型将提前至4月。结合此次开源的优化技术,R2的推理成本可能再降30%,并首次实现复杂推理任务(如数学证明)的“自然涌现”。有分析师警告:“如果R2真如爆料所言,OpenAI的GPT-4.5可能刚发布就要被吊打。”
2. 中国技术正在定义全球标准

中国标准
从MLA解码核到FP8 GEMM,DeepSeek连续四天开源的“基建组件”,已形成完整的AI训练工具链。更深远的影响是:中国团队首次将“算法优化”与“工程实现”打包开源,相当于把造车的图纸和发动机一起送人。难怪OpenCSG创始人陈冉感叹:“AI层要变天,不跟上就要被淘汰。”
结语:开源成为武器,中国AI正在“卷”出新高度
DeepSeek这场“技术核爆”,表面是优化训练效率,实则是在重新定义行业规则:开源不再只是情怀,而是降维打击的利器。
当中小团队能用现成工具复现万亿模型,当英伟达的算力焦虑蔓延至华尔街,这场由代码引发的革命,才刚刚开始!
欢迎评论区留言~
